tg-me.com/machinelearning_interview/1618
Last Update:
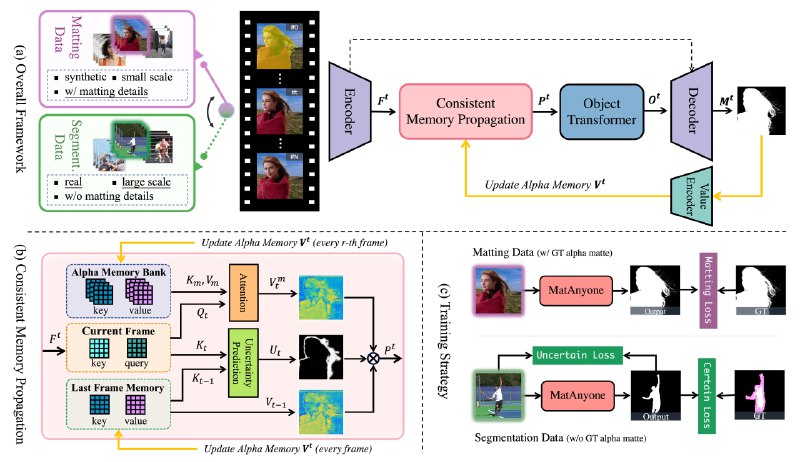
MatAnyOne - memory-based модель для видео-маттинга, разработанная для получения стабильных и точных результатов в сценариях реального постпродакшена. В отличие от методов, требующих дополнительного аннотирования, MatAnyOne использует только кадры видео и маску сегментации целевого объекта, определенную на первом кадре.
MatAnyOne оперирует регионально-адаптивным слиянием памяти, где области с небольшими изменениями сохраняют данные из предыдущего кадра, а области с большими изменениями больше полагаются на информацию из текущего кадра. Такая техника позволяет MatAnyOne эффективно отслеживать целевой объект, даже в сложных и неоднозначных сценах, сохраняя при этом четкие границы и целые части переднего плана.
При создании модели применялась уникальная стратегия обучения, которая опирается на данные сегментации для улучшения стабильности выделения объекта. В отличие от распространенных практик, MatAnyOne использует эти данные непосредственно в той же ветви, что и данные маски. Это достигается путем применения регионально-специфичных потерь: пиксельная потеря для основных областей и улучшенная DDC-потеря для граничных областей.
Для обучения был специально создан кастомный набор данных VM800, который вдвое больше, разнообразнее и качественнее, чем VideoMatte240K, что по итогу значительно улучшило надежность обучения объектному выделению на видео.
В тестах MatAnyOne показал высокие результаты по сравнению с существующими методами как на синтетических, так и на реальных видео:
⚠️ Согласно обсуждению в issues репозитория, MatAnyOne способен работать локально от 4 GB VRAM и выше с видео небольшой длительности. Реальных технических критериев разработчик не опубликовал.
# Clone Repo
git clone https://github.com/pq-yang/MatAnyone
cd MatAnyone
# Create Conda env and install dependencies
conda create -n matanyone python=3.8 -y
conda activate matanyone
pip install -e .
# Install python dependencies for gradio
pip3 install -r hugging_face/requirements.txt
# Launch the demo
python app.py
@ai_machinelearning_big_data
#AI #ML #VideoMatte #MatAnyone